
[Notes] CSCI 585 Distributed Database Management Systems
18 Feb 2020 | CSCI585, English/英文, NoteCredit to: Prof. Saty Raghavachary, CSCI 585, Spring 2020
outline
- About distributed database management systems (DDBMSs) and their components
- How database implementation is affected by different levels of data and process distribution
- How transactions are managed in a distributed database environment
- How distributed database design draws on data partitioning and replication to balance performance, scalability, and availability
- About the trade-offs of implementing a distributed data system
Chapter 12
Factors Affecting the Centralized Database Systems
- Globalization of business operation
- Advancement of web-based services
- Rapid growth of social and network technologies
- Digitization resulting in multiple types of data
- Innovative business intelligence through analysis of data
Evolution Database Management Systems
- Distributed database management system (DDBMS): Governs storage and processing of logically related data over interconnected computer systems
- Data and processing functions are distributed among several sites
- Centralized database management system
- Required that corporate data be stored in a single central site
- Data access provided through dumb terminals
Factors That Aided DDBMS to Cope With Technological Advancement
- Acceptance of Internet as a platform for business
- Mobile wireless revolution
- Usage of application as a service
- Focus on mobile business intelligence
Advantages and Disadvantages of DDBMS
- Advantages
- Data are located near greatest demand site
- Faster data access and processing
- Growth facilitation
- Improved communications
- Reduced operating costs
- User-friendly interface
- Less danger of a single-point failure
- Processor independence
- Disadvantages
- Complexity of management and control
- Technological difficulty
- Security
- Lack of standards
- Increased storage and infrastructure requirements
- Increased training cost
- Costs incurred due to the requirement of duplicated infrastructure
Distributed Processing and Distributed Databases
- Distributed processing: Database’s logical processing is shared among two or more physically independent sites via network
- Distributed database: Stores logically related database over two or more physically independent sites via computer network
- Database fragments: Database composed of many parts in distributed database system
Fully distributed DBMSs: functions
Distributed processing AND data storage -> ‘fully’ distributed.
Functions of Distributed DBMS
- Receives the request of an application
- Validates analyzes, and decomposes the request
- Maps the request
- Decomposes request into several I/O operations
- Searches and validates data
- Ensures consistency, security, and integrity
- Validates data for specific conditions
- Presents data in required format
transparency (hiding structure from people)
Figure 12.4 - A Fully Distributed Database Management System
DDBMS Components
- Computer workstations or remote devices
- Network hardware and software components
- Communications media
- Transaction processor (TP) (transaction manager (TM) or application processor (AP)): Software component of a system that requests data
- Receives data requests (from an application), and requests data (from a DP); also known as AP (Application Processor) or TM (Transaction Manager). A TP is what fulfills data requests on behalf of a transaction.
- Data processor (DP) or data manager (DM): Software component on a system that stores and retrieves data from its location
- receives data requests from a TP (in general, multiple TPs can request data from a single DP), retrieves and returns the requested data; also known as DM (Data Manager).
Data and processing distribution: 3 variations
| | single-site data | multiple-site data | | ——————— | ——————————————– | ———————————— | | single-site process | Host DBMS | - | | multiple-site process | Files server (client/server DBMS (LAN DBMS)) | Fully distributed Client/sever DDBMS |
Single-Site Processing, Single-Site Data (SPSD)
- Processing is done on a single host computer
- Data stored on host computer’s local disk
- Processing restricted on end user’s side
- DBMS is accessed by dumb terminals
Multiple-Site Processing, Single-Site Data (MPSD)
- Multiple processes run on different computers sharing a single data repository
- Require network file server running conventional applications
- Accessed through LAN
- Client/server architecture
- Reduces network traffic
- Processing is distributed
- Supports data at multiple sites
Figure 12.7 - Multiple-Site Processing, Single-Site Data
Multiple-Site Processing, Multiple-Site Data (MPMD)
- Fully distributed database management system
- Support multiple data processors and transaction processors at multiple sites
- Classification of DDBMS depending on the level of support for various types of databases
- Homogeneous: Integrate multiple instances of same DBMS over a network
- Heterogeneous: Integrate different types of DBMSs
- Fully heterogeneous: Support different DBMSs, each supporting different data model
Restrictions of DDBMS
- Remote access is provided on a read-only basis
- Restrictions on the number of remote tables that may be accessed in a single transaction
- Restrictions on the number of distinct databases that may be accessed
- Restrictions on the database model that may be accessed DDBMs span the spectrum from homegenous to fully heterogenous, and tend to come with restrictions.
Distributed Requests and Distributed Transactions
remote/localized requests and transactions
- Remote request
- Single SQL statement accesses data processed by a single remote database processor
- Remote transaction
- Accesses data at single remote site composed of several requests
distrbuted (not localize) requests and transactions
- Accesses data at single remote site composed of several requests
- Distributed transaction
- Requests data from several different remote sites on network
- Distributed request
- Single SQL statement references data at several DP sites
Distributed transactions are what need to be carefully executed so as to maintain distribution transparency - the transactions have to execute ‘as if’ they all ran on the same machine/location. This is achieved using ‘2PC’ [explained in upcoming slides].
Distributed Concurrency Control
- Concurrency control is important in distributed databases environment
- Due to multi-site multiple-process operations that create inconsistencies and deadlocked transactions Figure 12.14 - The Effect of Premature COMMIT
Two-Phase Commit Protocol (2PC)
- Guarantees if a portion of a transaction operation cannot be committed, all changes made at the other sites will be undone
- To maintain a consistent database state
- Requires that each DP’s transaction log entry be written before database fragment is updated
- DO-UNDO-REDO protocol: Roll transactions back and forward with the help of the system’s transaction log entries
- Write-ahead protocol: Forces the log entry to be written to permanent storage before actual operation takes place
- Defines operations between coordinator and subordinates
- Phases of implementation
- Preparation
- The final COMMIT
In the two phase commit protocol, as the name implies, there are two phases:
- phase 1: commit request phase, aka ‘voting’ phase: coordinator sends a ‘commit or abort?’ (aka ‘query to commit’ or ‘prepare to commit’) message to each participating transaction node; each node responds (votes), with a ‘can commit’ (aka ‘ready’) or ‘need to abort’ (aka ‘abort’) message
- phase 2: commit phase, aka ‘completion’ phase:
- if in phase 1, all nodes responded with ‘can commit’, the coordinator sends a ‘commit’ phase to each node; each node commits, and sends an acknowledgment to the coordinator
- or, if in phase 1, any node responded with ‘need to abort’, the coordinator sends an ‘abort’ message to each node; each node aborts, and sends an acknowledgment to the coordinator The devil’s in the details - all sorts of variations/refinements exist in implementations, but the above is the overall (simple, robust) idea.
It’s an all-or-nothing scheme - either all nodes of a distributed transaction locally commit (in which case the overall transaction is successful), or all of them locally abort so that the DB is not left in an inconsistent state unlike in the ‘Problem!’ slide (in which case the overall transaction fails and needs to be redone).
Distributed Database Transparency Features
Heterogeneity transparency
Distribution Transparency
- Allows management of physically dispersed database as if centralized
- Levels
- Fragmentation transparency
- Location transparency
- Local mapping transparency
- Distribution Transparency Unique fragment: Each row is unique, regardless of the fragment in which it is located Supported by distributed data dictionary (DDD) or distributed data catalog (DDC) DDC contains the description of the entire database as seen by the database administrator Distributed global schema: Common database schema to translate user requests into subqueries
Transaction Transparency
- Ensures database transactions will maintain distributed database’s integrity and consistency
- Ensures transaction completed only when all database sites involved complete their part
- Distributed database systems require complex mechanisms to manage transactions
Failure transparency
Ensures the system will operate in case of network failure
Performance transparency
Allows a DDBMS to perform as if it were a centralized database
Replica transparency: DDBMS’s ability to hide multiple copies of data from the user
- Network and node availability
- Network latency: delay imposed by the amount of time required for a data packet to make a round trip
- Network partitioning: delay imposed when nodes become suddenly unavailable due to a network failure
Distributed Database Design
- Data fragmentation: How to partition database into fragments (how many part)
- Breaks single object into many segments
- Information is stored in distributed data catalog (DDC)
- Strategies
- Horizontal fragmentation: Division of a relation into subsets (fragments) of tuples (rows)
- Vertical fragmentation: Division of a relation into attribute (column) subsets
- Mixed fragmentation: Combination of horizontal and vertical strategies
- Data replication
- Which fragments to replicate
- Data allocation
- Where to locate those fragments and replicas
Data Replication
- Data copies stored at multiple sites served by a computer network
- Mutual consistency rule: Replicated data fragments should be identical
- Styles of replication
- Push replication
- Pull replication
- Helps restore lost data
Data Replication Scenarios
- Fully replicated database
- Stores multiple copies of each database fragment at multiple sites
- Partially replicated database
- Stores multiple copies of some database fragments at multiple sites
- Unreplicated database
- Stores each database fragment at a single site
Data Allocation Strategies
- Centralized data allocation
- Entire database stored at one site
- Partitioned data allocation (not copy)
- Database is divided into two or more disjoined fragments and stored at two or more sites
- Replicated data allocation
- Copies of one or more database fragments are stored at several sites
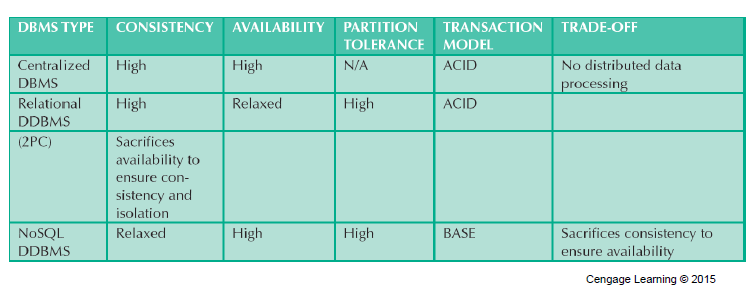
The CAP Theorem
The CAP theorem ‘used to say’ that in a networked (distributed) DB system, at most 2 out of 3 of the above are achievable. In today’s systems, it is a bit different: in the event of a network partition, only one of availability or consistency is achievable.
- CAP stands for:
- Consistency: always correct data.
- Availability: requests are always filled.
- Partition (“outage”) tolerance continue to operate even if (some/most) nodes fail.
- Basically available, soft state, eventually consistent (BASE) (when consistency sacrifice)
- Data changes are not immediate but propagate slowly through the system until all replicas are consistent
In the ‘ACID’ (Atomicity, Consistency, Isolation, Durability) world of older relational DBs, the CAP Theorem was a reminder that it is usually difficult to achieve C,A,P all at once, and that consistency is more important than availability.
In today’s ‘BASE’ (Basically Available, Soft_state, Eventually_consistent) model of non-relational (eg. NoSQL) DBs, we prefer to sacrifice consistency in favor of availability.
Date’s ‘12 commandments’ for distributed DBMSs
| RULE NUMBER | RULE NAME | RULE EXPLANATION |
|---|---|---|
| 1 | local-site independence | each local site can act as an independent, autonomous centralized DBMS. Each site is responsible for security, concurrency control, backup, and recovery. |
| 2 | central-site independence | No site in the network relies on a central site or any other side. All sites have teh same capabilities. |
| 3 | failure independence | the system is not affected by node failures. The system is in continuous operation even in the case of a node failure or an expansion of the network. |
| 4 | location transparency | The user does not need to know the location of data to retrieve those data |
| 5 | fragmentation transparency | Data fragmentation is transparent to the user, who sees only one logical database. The user does not need to known the name of the data base fragment to retrieve them. |
| 6 | replicaiton transparency | The user sees only on logical database. The DDBMS transparently selects the database fragment to access. To the user, the DDBMS manages all fragments transparently. |
| 7 | Distributed query processing | A distributed query may be executed at several different DP sites. Query optimization is performed transparently by the DDBMS. |
| 8 | Distributed transaction processing | A transaction may update data at several different sites, and the transaction is executed transparently. |
| 9 | Hardware independence | The system must run on any hardware platform. |
| 10 | Operation system independence | The system must run on any operation system platform. |
| 11 | Network independence | The system must run on any network platform. |
| 12 | Database independence | The system must support any vendor’s database product. |