
[Notes] CSCI 585 DB (DE/)Normalization
28 Jan 2020 | CSCI585, English/英文, NoteCredit to: Prof. Saty Raghavachary, CSCI 585, Spring 2020
outline
- What normalization is and what role it plays in the database design process
- About the normal forms 1NF, 2NF, 3NF, BCNF, and 4NF
- How normal forms can be transformed from lower normal forms to higher normal forms
- That normalization and ER modeling are used concurrently to produce a good database design
- That some situations require denormalization to generate information efficiently
Normalization
Correct one table each time
- Evaluating and correcting table structures to minimize data redundancies
- Reduces data anomalies
- Assigns attributes to tables based on determination
- Normal forms (higher normal forms -> cleaner the designss)
- First normal form (1NF)
- Second normal form (2NF)
- Third normal form (3NF)
- Structural point of view of normal forms
- Higher normal forms are better than lower normal forms
- Properly designed 3NF structures meet the requirement of fourth normal form (4NF)
- Denormalization: Produces a lower normal form
- Results in increased performance and greater data redundancy
Need for Normalization
- Results in increased performance and greater data redundancy
- Used while designing a new database structure
- Analyzes the relationship among the attributes within each entity
- Determines if the structure can be improved
- Improves the existing data structure and creates an appropriate database design
Example
Employees of the construction company work on projects. Each employee has an ID, name, job title and corresponding hourly rate.
Each project has a number, name and assigned employees. An employee can be assigned to more than one project.
The company bills clients for projects, based on hours worked by employees.
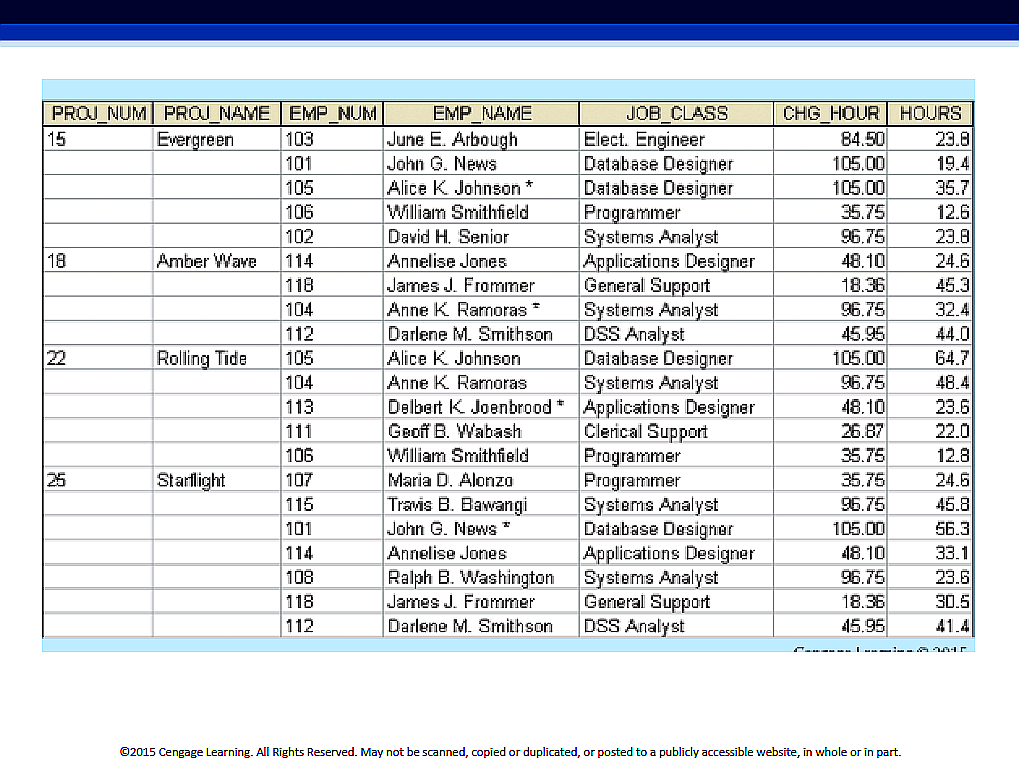
There are numerous issues:
- the PROJ_NUM attr could be used as a PK (or part of a PK, along with PROJ_NAME) but it contains nulls
- possibilities for data inconsistencies exist, eg. if someone’s name or title is misspelled
- the redundancies that exist, could lead to insertion anomalies (eg. a new employee needs to be assigned to some project, even a fake one), update anomalies (eg. if an employee’s JOB_CLASS changes, it has to be modified multiple times), deletion anomalies (eg. if a project has just one employee and that employee leaves, deleting the lone employee record would lead to the project itself getting deleted!)
- data redundancy leads to wasted storage space
We have ‘repeating groups’ (for each project, we list all details about each employee) - our table is un-normalized, ie. is in ‘0NF’ :)
So, we need to clean up the design!
Normalization Process
- Normalization is a systematic process that yields progressively higher ‘normal forms’ (NFs) for each entity (table) in our db. We want at least 3NF for each table; in RL, we stop at 3NF.
- Objective is to ensure that each table conforms to the concept of well-formed relations
- Each table represents a single subject
- No data item will be unnecessarily stored in more than one table
- All nonprime attributes in a table are dependent on the primary key (wholly; nothing but)
- Each table is void of insertion, update, and deletion anomalies
- Ensures that all tables are in at least 3NF
- Higher forms are not likely to be encountered in business environment
- Works one relation at a time
- Starts by:
- Identifying the dependencies of a relation (table)
- Progressively breaking the relation into new set of relations

Normalization how-to, in one sentence: work on one relation (table) at a time: identify dependencies, then ‘normalize’ - progressively break it down into smaller relations (tables), based on the dependencies we identify in the original relation.
Functional Dependence Concepts
| Concept | Definition |
|---|---|
| Functional dependence | The attribute B is fully functionally dependent on the attribute A if each value of A determines one and only one value of B. |
| Functional dependence (Generalized definition) | Attribute A determines attribute B if all of the rows in the table that agree in value for attribute A also agree in value for attribute B. |
| Fully functional dependence (composite key) | If attribute B is functionally dependent on a composite key A but not on any Subset of that composite key, the attribute B is fully functionally dependent on A. |
Types of Functional Dependencies
- Partial dependency: Functional dependence in which the determinant is only part of the primary key
- Assumption - One candidate key
- Straight forward
- Easy to identify
- Transitive dependency: An attribute functionally depends on another nonkey attribute
If (A,B) is a primary key, we have partial dependence if (A,B)->(C,D) and B->C [C is only partially dependent on the PK, ie. we only need B to determine C].
Conversion to First Normal Form (0NF -> 1NF)
eliminate repeating groups
- Repeating group: Group of multiple entries of same type can exist for any single key attribute occurrence
- Existence proves the presence of data redundancies
- Enable reducing data redundancies
- Steps
- Eliminate the repeating groups
- Identify the primary key
- Identify all dependencies
- Dependency diagram: Depicts all dependencies found within given table structure
- Helps to get an overview of all relationships among table’s attributes
- Makes it less likely that an important dependency will be overlooked
- Create a dependency diagram, showing relationships (dependencies) between the attributes - this will help us systematically normalize the table.
Indicate full dependencies on the top, and partial and transitive dependencies on the bottom. “Top good, bottom bad”. Also, color the PK components in a different color (and underline them). Result:
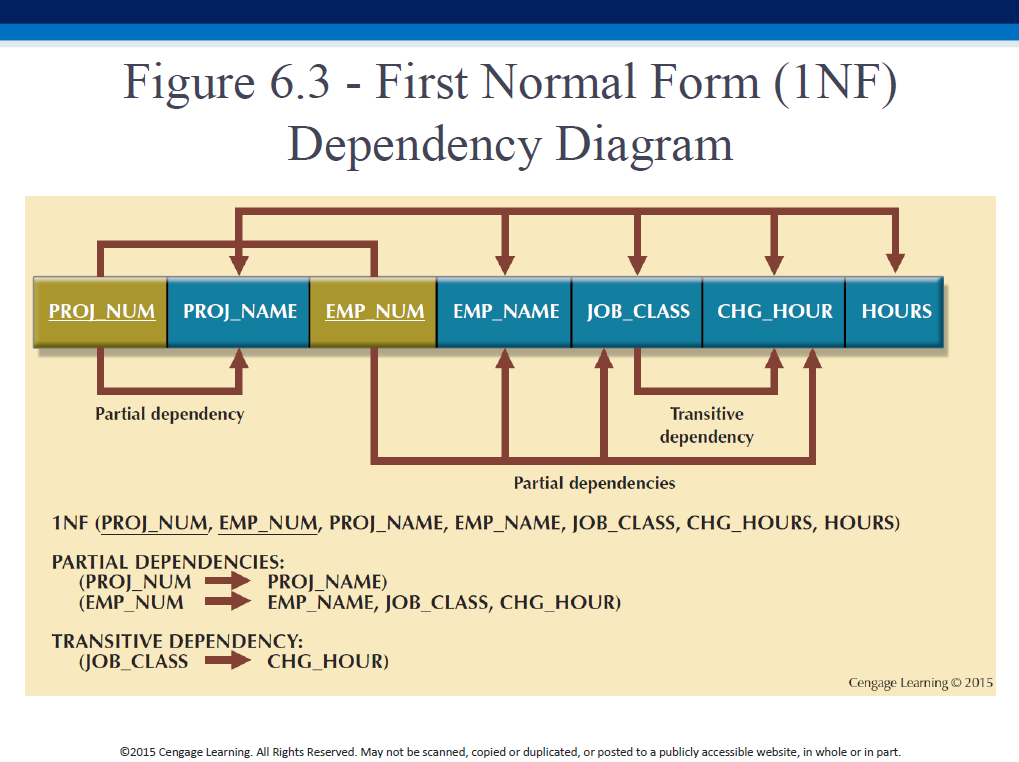
PROJ_NAME has only a partial dependency on the PK (since it is only dependent on PROJ_NUM, which is just a part of the PK).
CHG_HOUR is dependent on JOB_CLASS, which is a non-prime attribute that is itself dependent on EMP_NUM. So JOB_CLASS->CHG_HOUR is a signaling dependency, indicating a EMP_NUM -> CHG_HOUR transitive dependency.
- 1NF describes tabular format in which:
- All key attributes are defined
- There are no repeating groups in the table
- All attributes are dependent on the primary key
- All relational tables satisfy 1NF requirements
- Some tables contain partial dependencies
- Subject to data redundancies and various anomalies
Conversion to Second Normal Form (1NF->2NF)
remove partial dependencies
- Steps
- Make new tables to eliminate partial dependencies
- Reassign corresponding dependent attributes
- Table is in 2NF when it:
- Is in 1NF
- Includes no partial dependencies

We eliminate partial dependencies by creating separate tables of such dependencies, and removing the dependent attributes from the starter table.
Conversion to Third Normal Form (2NF->3NF)
We promote the non-prime keys that masquerade as PKs, into actual PKs (give them their own tables).
Whether we eliminate partial dependencies (to create 2NF) or transitive ones (to create 3NF), we follow the same process: create a new relation for each ‘problem’ dependency!
- Steps
- Make new tables to eliminate transitive dependencies
- Determinant: Any attribute whose value determines other values within a - row
- Reassign corresponding dependent attributes
- Make new tables to eliminate transitive dependencies
- Table is in 3NF when it:
- Is in 2NF
- Contains no transitive dependencies

Requirements for Good Normalized Set of Tables
- Evaluate PK assignments and naming conventions
- Refine attribute atomicity
- Atomic attribute: Cannot be further subdivided
- Atomicity: Characteristic of an atomic attribute
- Identify new attributes and new relationships
- Refine primary keys as required for data granularity
- Granularity: Level of detail represented by the values stored in a table’s row
- Maintain historical accuracy and evaluate using derived attributes
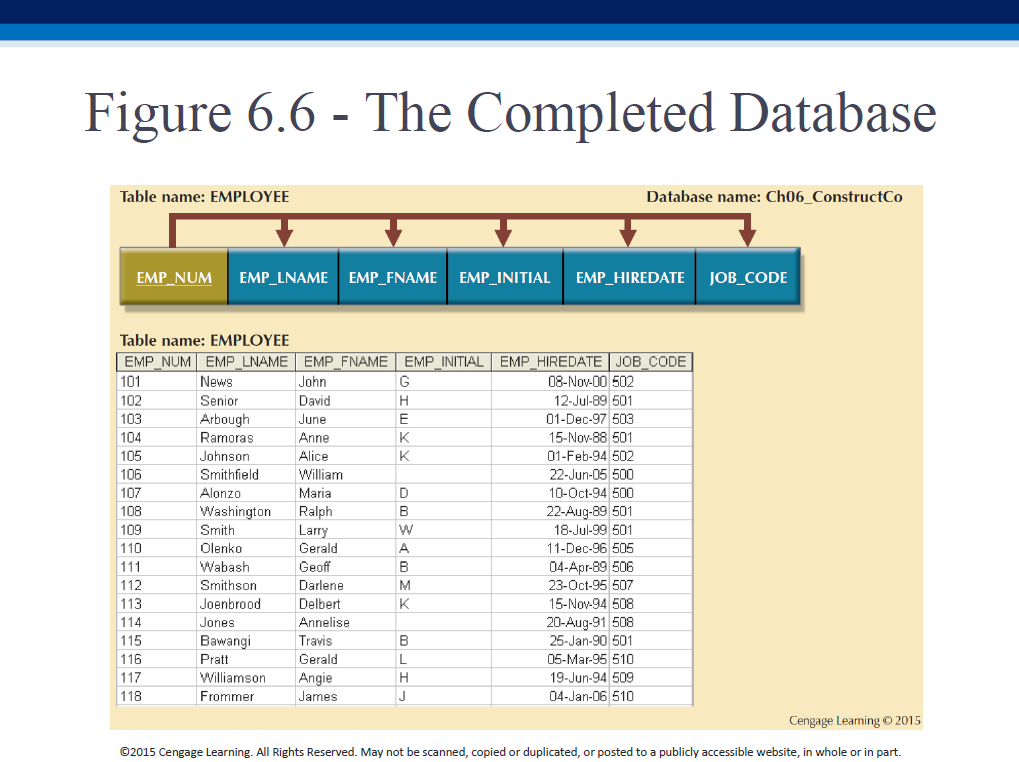
Good table (towards example)
We can create a better DB by doing the following augmentations, to the 3NF model we just created:
- evaluate PKs - create a JOB_CODE
- evaluate naming conventions - eg. JOB_CHG_HOUR
- refine attr atomicity, eg. EMP_NAME
- identify new attrs, eg. EMP_HIREDATE
- identify new relationships, PROJECT can have EMP_NUM as FK [to be able to - record a project’s (always sole) manager]
- refine PKs for data granularity, eg. ASSIGN_NUM
- maintain historical accuracy [duplicate data], eg. store JOB_CHG_HOUR in - ASSIGNMENT
- evaluate derived attrs, eg. ASSIGN_CHARGE

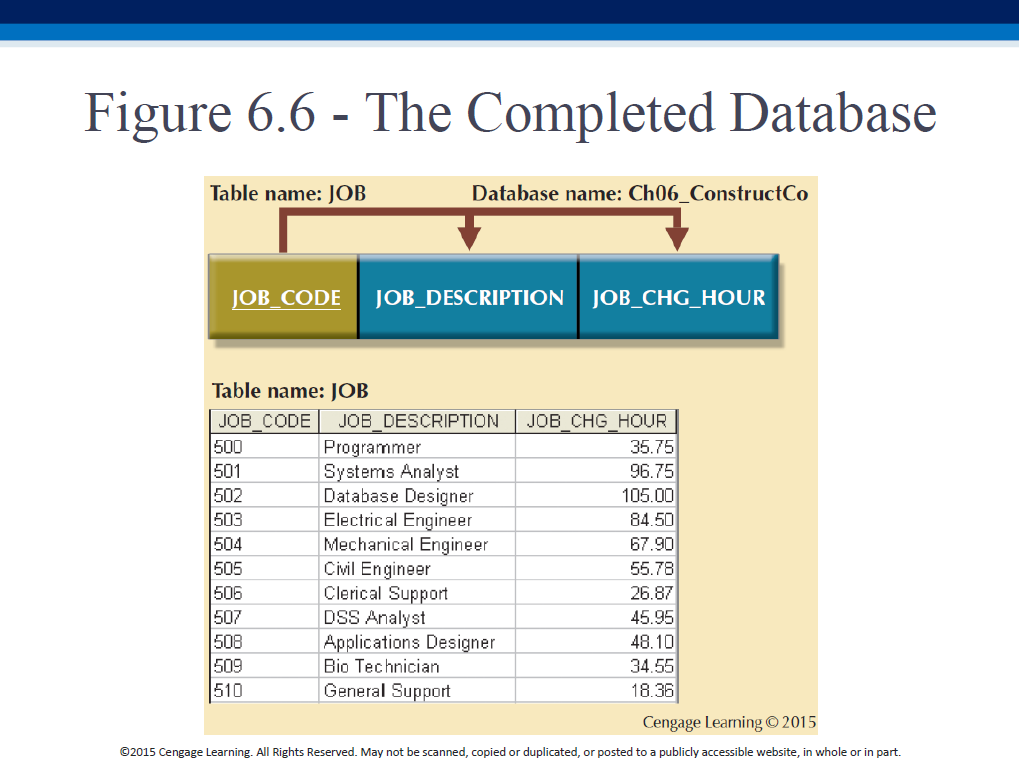
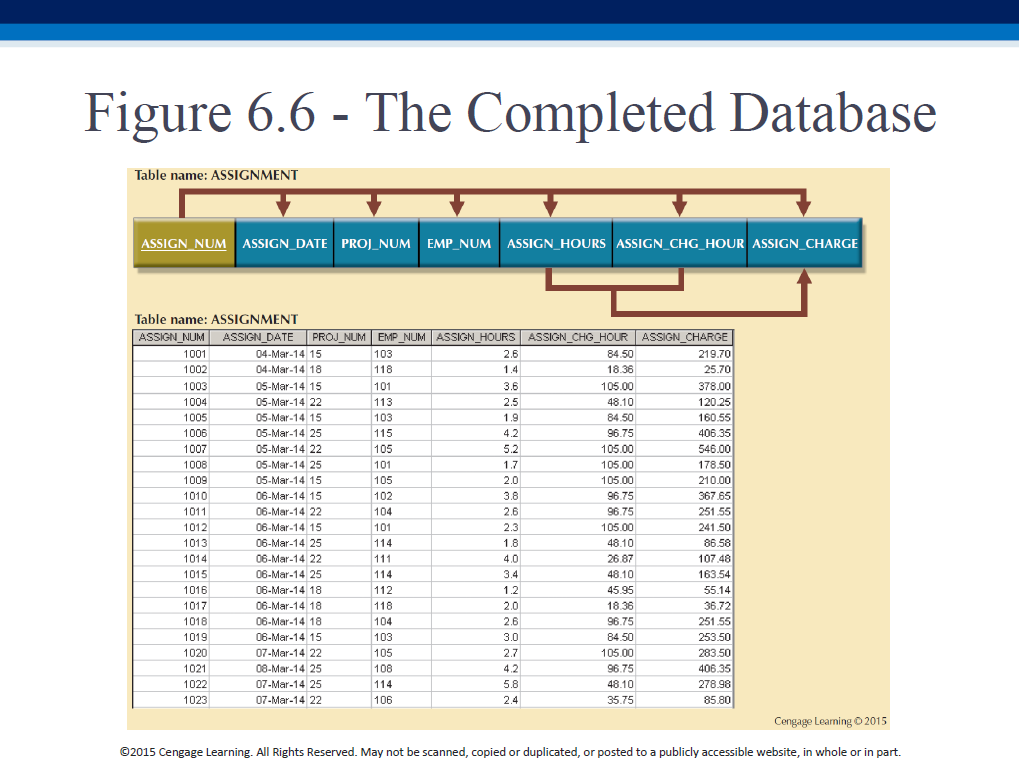
Normalization: summary
- 1NF: eliminate repeating groups (partial:y, transitive:y)
- 2NF: eliminate redundant data (partial:n, transitive:y)
- 3NF: eliminate fields not dependent on key fields (partial:n, transitive:n)
Denormalization
- Design goals
- Creation of normalized relations
- Processing requirements and speed
- Number of database tables expands when tables are decomposed to conform - to normalization requirements
- Joining a larger number of tables:
- Takes additional input/output (I/O) operations and processing logic
- Reduces system speed
- Defects in unnormalized tables
- Data updates are less efficient because tables are larger
- Indexing is more cumbersome
- No simple strategies for creating virtual tables known as views