TensorFlow快速入门与实战笔记(1)
24 Feb 2019 | Chinese/中文, IT, Note本文是在学习课程TensorFlow快速入门与实战时的笔记
目录
模块与架构
API
不同级别的API
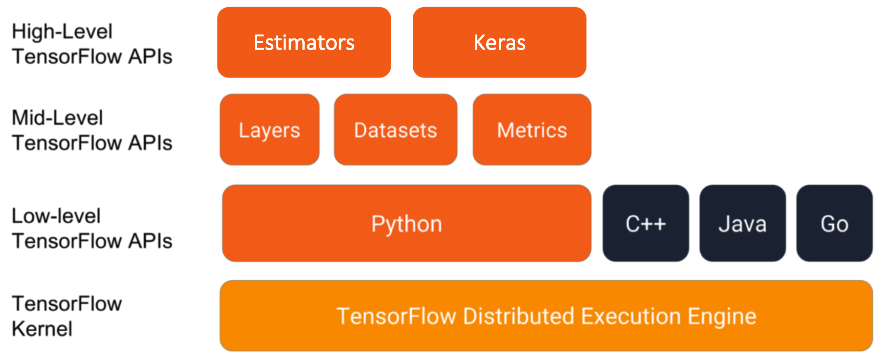
架构
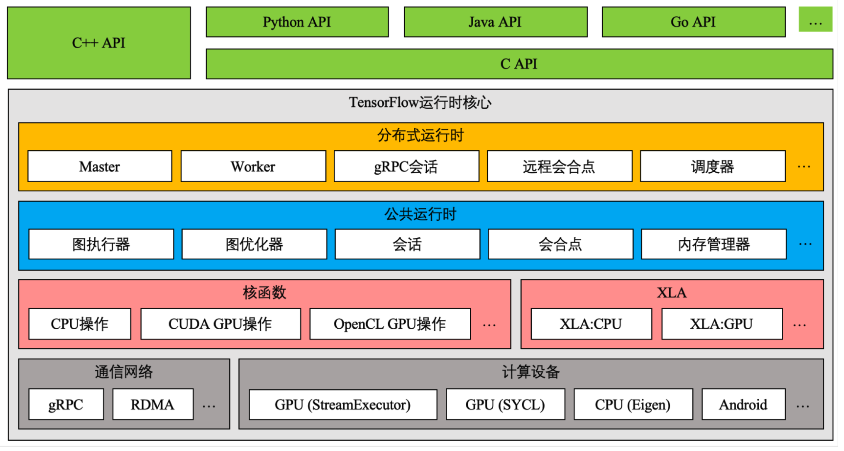
在应用层,几种语言的 API 都是建立在 C API的封装(除了C++拥有一套完整的封装)
运行核心实现了一些运算中的关键数据结构。具体而言包含Tensor和相关操作的定义等等。
而运行操作是由下面的核函数实现的。
XLA,通过中间表示层和编译器的优化,将可化简的运算合并为更大粒度的运算提高效率。
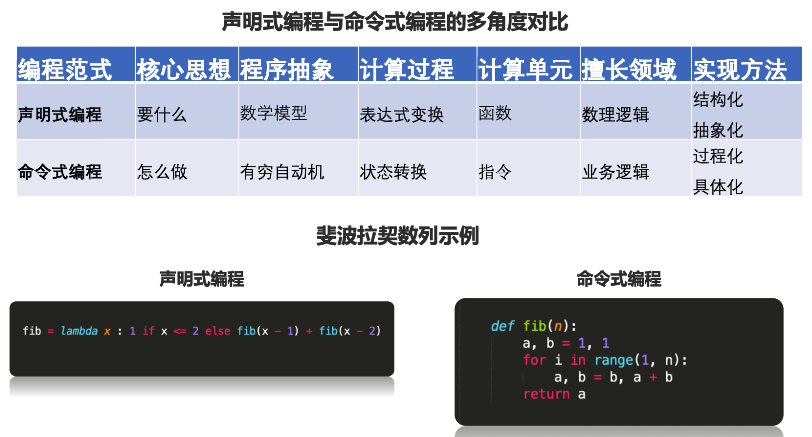
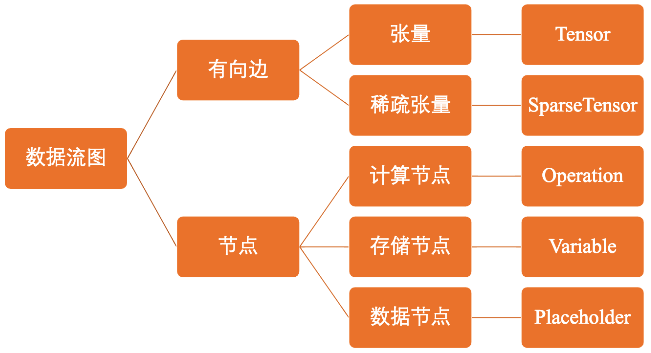
数据流图
TensorFlow 数据流腿是一种声明式的编程范式。相比命令式更加靠近目的,靠近数理逻辑。
更加适用于结构化抽象画。
从入度为零的点开始计算。
优势
- 并行计算快(损耗低)
- 分布式计算快(CPUs,GPUs,TPUs)
- 预编译优化(XLA)
- 可移植性好(Language-independent representation)
Tensor
在数学中张量是一种几何实体,广义上表示任意形式的“数据”。 张量可以理解标量,向量等数据实体在高维空间上的推广。 在TensorFlow中,Tensor表示相同数据类型的多维数组。 因此,它具有两个重要的属性:
- 数据类型(e.g 浮点型)
- 数组形状(各个维度的大小,i.e shape)
Notice:
- 张量是用来表示多维数据的
- 是执行操作时的输入或输出数据
- 用户通过执行操作来创建或计算张量
- 张量的形状可以部分定义,允许在运行时通过形状推断计算得出
常用张量
tf.constant //常量tf.placeholder //占位符tf.Varibale //变量
示例代码
mystr = tf.Variable(['Hello', 'World'], tf.string)
# out put: <tf.Variable 'Variable_0' shape=(2,) dtype=string_ref>Variable
维护特定节点的状态,如模型参数。
tf.Variable 是一个操作,返回值是一种特殊张量(不依赖计算,不会被清理,常驻内存)
示例代码
import tensorflow as tf
# 创建变量
w = tf.Variable(<initial-value>, name=<optinal-name>)
# 将变量作为操作输入
y = tf.sigmoid(w + y)
# 重新给变量赋值
w.assign(w + 1.0)
w.assign_add(1.0)Notice:这里仅仅是在描述,没有真正进行计算
变量使用流程
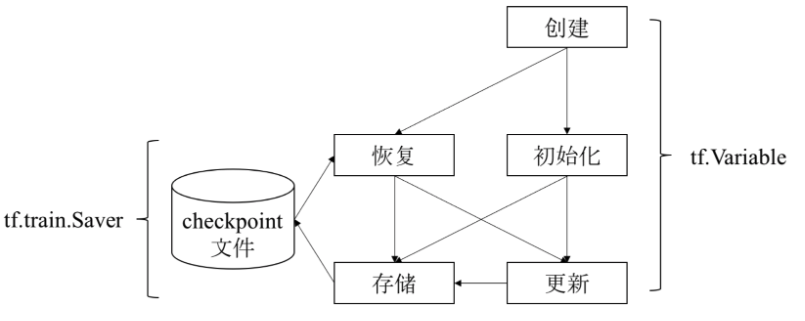
v1 = tf.Variable(..., name='v1')
v2 = tf.Variable(..., name='v2')
# 指定需要保存和恢复的变量
saver = tf.train.Saver({'v1': v1, 'v2': v2})
saver = tf.train.Saver([v1, v2])
saver = tf.train.Saver({v.op.name: v for v in [v1, v2]}) # 与上一行相同
# 保存变量的方法 (global_step 设置比较重要)
tf.train.saver.save(sess, 'my-model', global_step=0) # ==> filename: 'my-model-0'
# 从文件中恢复变量
saver.restore(sess, 'my-model-0')
# 从文件中恢复数据流图结构
# tf.train.import_meta_graphOperation
在TensorFlow的数据流图中,每个节点对应一个具体操作。因此,操作时模型功能的实际载体。 按照功能粉丝一下三种:
- 储存节点:有状态的变量操作,通常用来存储型参数;
- 计算节点:无状态的计算或控制操作,主要负责算法逻辑表达或流程控制;
- 数据节点:数据的占位符操作,用于描述图外输入数据的属性;
典型的计算和控制操作
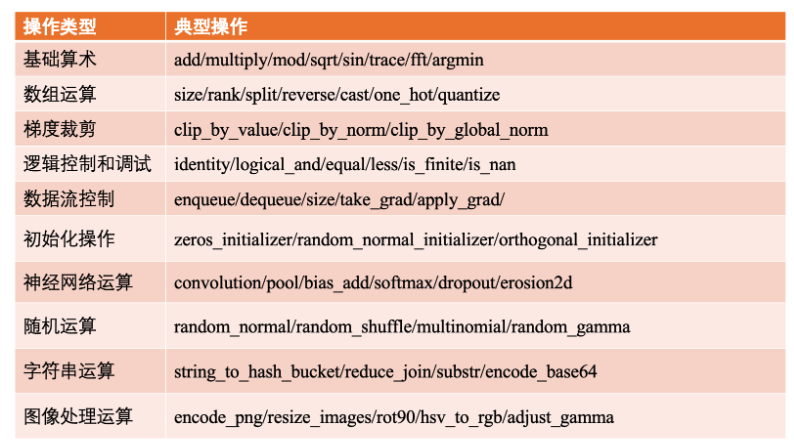
Placeholder
表示图外输入的数据,e.g训练和测试数据。 数据流图描述了算法模型的计算拓扑,其中的各个操作(节点)都是抽象的函数映射或数学表达式。 换句话说,数据流图本身知识一个具有计算拓扑和内部结构的“壳”(类似都代数式)。 在用户向其填充数据之前,图中没有真正执行任何计算。 因此,在TensorFlow中尽量避免使用逻辑控制。
x = tf.placeholder(tf.int16, shape=(), name="x")
y = tf.placeholder(tf.int16, shape=(), name="y")
with tf.Session() as sess:
print(sess.run(add, feed_dict={x: 2, y: 3}))
print(sess.run(mul, feed_dict={x: 2, y: 3}))Session
会话提供了估算张量和执行操作的运行环境,它是发放计算任务的客户端,所有计算任务都由他连接的执行引擎完成。
# 1.创建会话
# target: 连接的执行引擎
# graph: 加载的数据流图
# config: 启动时配置
sess = tf.Session(target=..., graph=..., config=...)
# 2.执行计算
sess.run(...)
# 3.关闭会话
sess.close()import tensorflow as tf
# 创建数据流图:z = x * y
# 也可以使用常量
# tf.constant(3.0, name='x')
x = tf.placeholder(tf.float32, name='x')
y = tf.placeholder(tf.float32, name='y')
z = tf.multiply(x, y, name='z')
# 创建会话
sess = tf.Session()
# 向数据节点x和y分别填充浮点数3.0和2.0,并输出结构
print(sess.run(z, feed_dict={x: 3.0, y:2.0}))
'''
输出6.0
'''会话操作
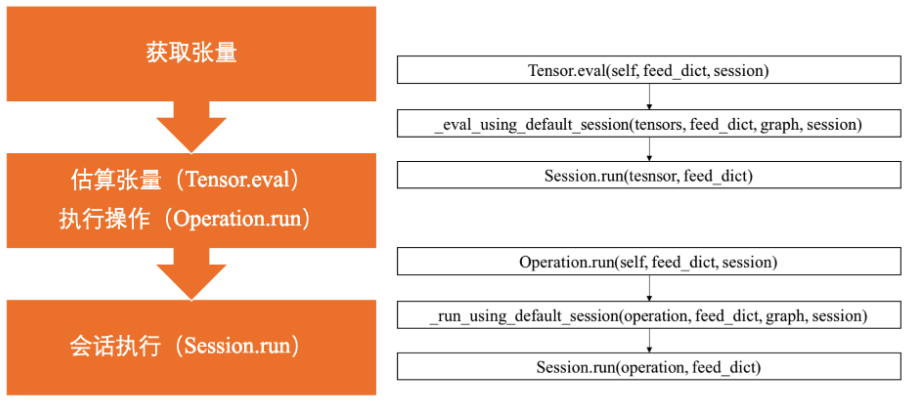 获取张量值的另外两种方法:估算张量(
获取张量值的另外两种方法:估算张量(Tensor.eval)与执行操作(Operation.run)
import tensorflow as tf
# 创建数据流图:y = W * x + b,其中W和b为存储节点,x为数据节点。
x = tf.placeholder(tf.float32)
W = tf.Variable(1.0)
b = tf.Variable(1.0)
y = W * x + b
with tf.Session() as sess:
tf.global_variables_initializer().run() # Operation.run
fetch = y.eval(feed_dict={x: 3.0}) # Tensor.eval
print(fetch) # fetch = 1.0 * 3.0 + 1.0估算最终都会调用Session.run()
执行原理
当我们调用sess.run(train_op)语句执行训练时:
- 程序内部提取操作依赖的所有前置操作。这些操作的节点共同组成一幅子图。
- 程序会将子图中的计算、储存和数据节点, 按照各自的执行设备分类,在相同设备上组成一幅局部图。
- 每个设备上的局部图在实际执行时, 根据节点时间的依赖关系将各个节点有序的加载到设备上执行
本地执行
可以在创建节点时指定相应的执行设备。
# or "\gpu:0"
with tf.device("/cpu:0"):
v = tf.Variable(...)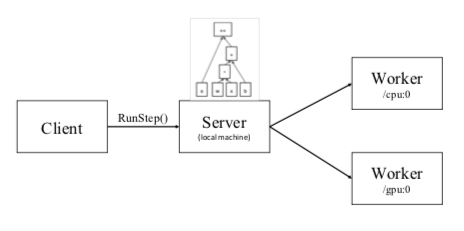
Optimizer
训练机制
- 模型:
y = f(x) = w * x + b,其中x是输入数据,y是模型输出的推理值,w和b是模型参数(训练的对象)。 - 损失函数:
loss = L(y,y_-),其中y_是x对应真实值,loss为损失函数输出的损失值。 - 优化算法:
w <- w + alpha * grad(w), b <- b + alpha * grad(b),其中grad(w)和grad(b)分别表示当损失值为loss时,模型参数w和b各自的梯度值,alpha为学习率。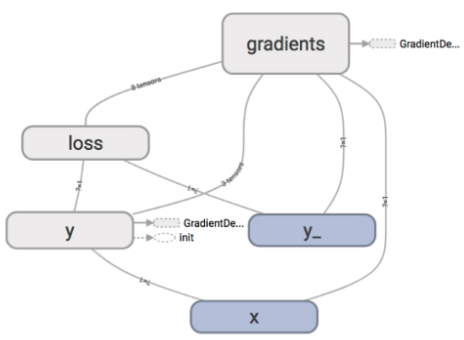
优化器
优化器是实现优化算法个的载体。 一次典型的迭代优化应分为一下三个步骤:
- 计算梯度:调用compute_gradients方法;
- 处理梯度:按需处理梯度值,e.g.梯度裁剪和梯度加权等;
- 应用梯度:调用apply_gradients方法,将处理后的梯度值应用到模型参数中
# step 1
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
grads_and_vars = optimizer.compute_gradients(loss,var_list, ...)
# step 2
clip_grads_and_var = [(tf.clip_by_value(grad, -1.0, 1.0), var)
for grad, var in grads_and_vars]
# step 3
train_op = optimizer.apply_gradients(clip_grads_and_vars)# 直接使用梯度
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)内置优化器